In the era of digital data explosion, the need to collect and process information from the Internet is becoming increasingly urgent. This is the time Web Scraping Serves as a powerful alternative to time-consuming and resource-intensive manual data collection methods.
So What is Web Scraping? How does it work and what value does it bring to individuals or businesses? Let's find out Hidemium Discover the important things you need to know before you start using this technology.
1. What is Web Scraping?
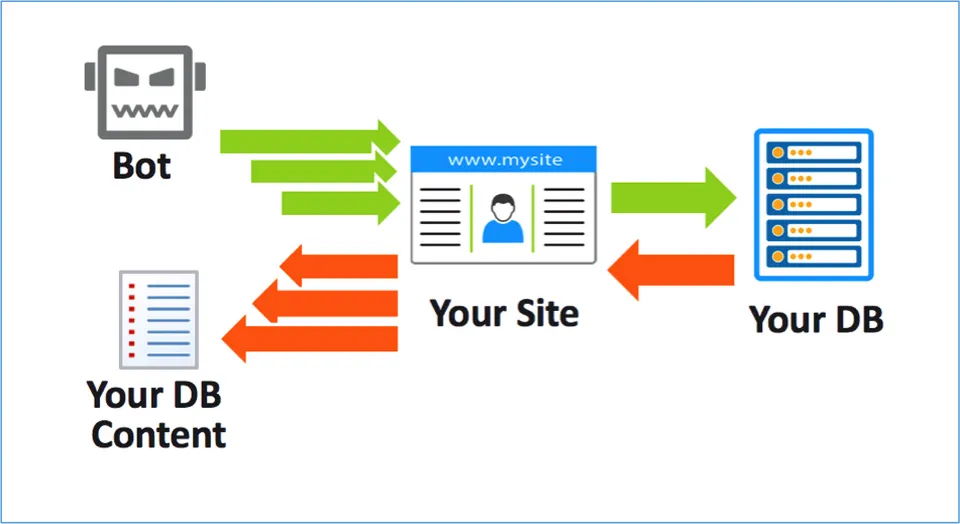
Web Scraping is the technique of automatically collecting information from websites through software or code called boots These boots will access the HTML source code of the website, extract the necessary data and save it as spreadsheet file, database, or integrated through API, serving purposes such as: market research, updating product data, competitor analysis, etc.
The tool that performs this process is called Web Scraper. Web Scraper is designed to scan and analyze the structure of a website, identify elements containing important information (e.g. prices, product names, article content) and automatically collect them according to predefined configurations.

>>> Learn more: What is WebRTC? Do websites collect WebRTC fingerprints?
2. What is Web Scraping used for?
Web Scraping is a technique of collecting data from websites automatically, which is currently widely applied in many different fields. Below are the most common purposes of Web Scraping:
Collect market data: Helps businesses quickly access information about prices, customer feedback and consumption trends from e-commerce sites, effectively supporting Competitive analysis and market research.
Social research and analysis: Web Scraping tools can get data from online newspapers, forums, blogs or government websites to serve the purpose of evaluating trends, public opinion and user behavior.
Automatically update news: The system can continuously collect the latest news from reputable sources, helping users update information quickly without having to manually monitor each page.
Collect product and service data: In the field of e-commerce, using Web Scraper to get data from competitors helps businesses grasp the market and adjust product strategies effectively.
Optimize advertising and marketing campaigns: Information about customer and competitor behavior obtained through Web Scraping will be an important foundation for businesses to improve efficiency digital marketing.
Track and compare prices online: This tool helps users and businesses monitor product or service prices from multiple sources, making it easy to find the best price.
Multi-source data aggregation: Web Scraper supports data collection from multiple websites, creating a comprehensive data warehouse for in-depth analysis and business decision making.
Content Automation: The data collected can be processed to automatically generate content for websites, blogs or applications, saving time on manual content production.
>>> Learn more: How to recognize antidetect with good fake Webrtc function
3. Web Scraping Applications in Prominent Fields
According to statistics from LinkedIn in the US, Web Scraping Has been widely applied in more than 54 different fields. Below is 10 typical industries with the highest rate of Web Scraping usage:
Computer software – 22%
Information technology & digital services – 21%
Finance – banking – insurance – 16%
(including: financial services 12%, insurance 2%, banking 2%)Internet and online platforms – 11%
Digital Advertising & Marketing – 5%
Cyber Security & Information Security – 3%
Management Consulting – 2%
Digital Media and Publishing – 2%
This shows thatWeb Scraping is not only useful in the technology field, but also an important tool inCollect market data, monitor competitors, track trends, and automate user analytics in many different industries.
>>> Learn more: What is Pixel Tracking? 3 Most Common Types of Pixel Tracking
4. The most popular types of Web Scrapers today
Web Scraper is a tool that automatically collects data from websites. Based on technical criteria and user experience, Web Scraper can be classified as follows:
4.1. By construction method: Self-built and Pre-built
Self-built: Programmed exclusively in popular languages such as Python, Java or Node.js. This type requires users to have programming skills and in-depth understanding of web systems.
Pre-built (available): Are libraries and support tools such as Scrapy, BeautifulSoup (Python) or Puppeteer (JavaScript). Suitable for users who want to deploy quickly and do not need to build from scratch.
4.2. By deployment type: Browser extension vs Standalone software
Browser Extension: Is an extension integrated into the browser, allowing to get data directly from the website being visited.
Software: Are standalone applications, installed on the computer, capable of operating separately from the browser, often powerful and highly customizable.
4.3. By user interface: With UI vs Without UI
With UI: Has an intuitive graphical interface, easy to use for non-technical people.
Without UI: Operates via command line (CLI), requires programming skills and is suitable for advanced developers.
4.4. By data storage and processing location: Cloud-based vs Local
Cloud-based: Cloud-based tools that support flexible data processing and storage, scale on demand, and are independent of user devices.
Local: Install and run directly on personal computers. Users need to configure, maintain and be responsible for system performance.
>>> Learn more: What is a User Agent? How to change UA on 4 popular browsers today
5. How does Web Scraping work?
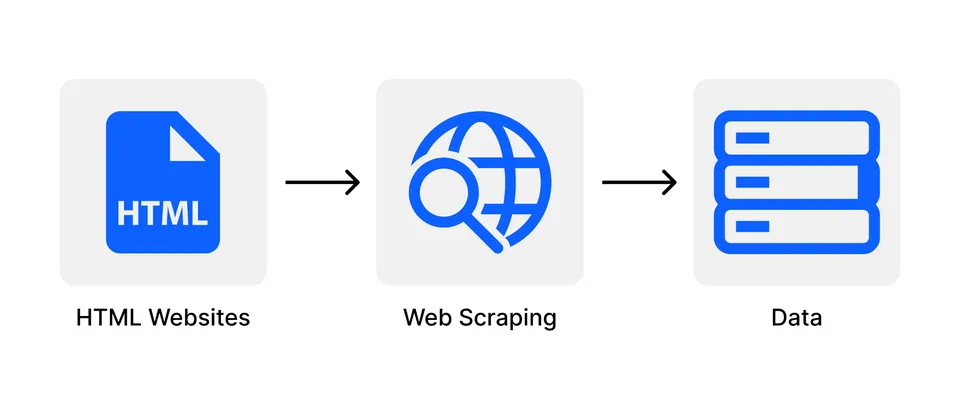
Web Scraping is the automated process of collecting data from websites, widely used in market research, price tracking, content analysis and many other purposes. To get started, you need to enter URL of the target website into the Scraper tool. The tool will then download the entire HTML code of the page – including JavaScript and CSS if necessary.
Users can select specific types of data they want to extract such as: product price, size, article title or detailed content. The scraper will then crawl the relevant pages to collect the corresponding information. If the website has a static structure, the data can be configured automatically. However, for most dynamic pages, the user needs to set it up manually due to the different HTML structures.
The collected data will be exported in popular formats such as CSV, Excel or JSON – ideal format for integration with API systems.
In spite of Web Scraping is a powerful tool for large-scale data processing and mining, but it is not always easy to deploy, especially for those who need it run multiple accounts or perform advanced automation. Many websites today have implemented security measures such as block IP, detect strange device, causing data collection to be interrupted.
Here is why Hidemium AntiDetect Browser becomes the ideal choice. Hidemium allows you to Manage multiple browser profiles, combined use Proxy to change IP address and device trace, help you bypass website security barriers effectively and safely.
In short, Web Scraping is a great way to collect information in the digital age, but it comes with important legal and ethical considerations. Always make sure that data collection is done legally. If you need assistance with tools or implementation, don't hesitate to contact us Hidemium for detailed advice.
>>> Related articles:

Related Blogs

Are you looking for a free VPN tool to change IP, access blocked websites and increase security when surfing the web? Kiwi VPN is a solution highly appreciated by many users. However, is Kiwi VPN secure and reliable enough? Let's explore details with Antidetect Browser Hidemium right below.1. What is Kiwi VPN?Kiwi VPN is a free VPN app that allows users to stay anonymous on the internet, bypass[…]

1. What is iProxy.online? iProxy.online is an Android application that allows you to set up a mobile proxy using your own phone. This means that the proxy will utilize the mobile internet on your phone, and the mobile proxy provider will match the proxy with one of your phone’s SIM cards. For example: If your […]
.png)
Are you looking for ways to access websites that are restricted at school, work, or in your area? We have compiled a list of the top 5 unblocked browsers to help you bypass any barriers easily. These browsers don’t require advanced tech skills, so you can start right away.1. What Are Unblocked Browsers?An unblocked browser is a tool that allows you to access websites that are restricted by your[…]

In the digital era, making money online (MMO) has become a popular trend, offering flexible and accessible opportunities for everyone. Whether you want to earn extra income or build a long-term business, there are always suitable options available. However, for beginners, the abundance of information can be overwhelming. Don’t worry! This article will guide you through 22 practical ways to make[…]


Two-factor authentication (2FA) is one of the most effective methods to protect your account from common security threats. In this article, Hidemium will guide you step-by-step through enabling 2FA on popular platforms, explaining why the feature is important and how it helps improve personal information security.1. What is 2FA? A Simple Explanation for BeginnersTwo-Factor Authentication (2FA) is[…]
